Income Assessment
This tutorial is based on models trained on the Census Income dataset ☍. These models were trained to predict whether a person earns more than USD 50 a year or not.
As in the first tutorial, we assume that a model is already trained for use in FixOut. The first steps regarding the necessary imports are the same as the first tutorial, so please check it out (Tutorial 1 – Credit Risk) before continue this one.
You can import the data directly from the FixOut package, as Census is a toy dataset, then call importAdultData.
from demo_data import importAdultData
We initialize the class responsible for running FixOut (FixOutRunner ☍) and assign it a name (which will be the title displayed on the web interface). We also indicate the sensitive features. In this case, they are “Marital status”, “race”, and “sex”.
⚠
FixOut is a tool centered on sensitive features and their proxies. Not providing this information correctly beforehand will compromise the obtained results.
fxo = FixOutRunner("Income Assessment (Census data)")
sensitive_features = ["Marital Status","Race","Sex"]
fxa = FixOutArtifact(model=model,
training_data=(X_train,y_train),
testing_data=[(X_test,y_test,"Testing")],
features_name=features_name,
sensitive_features=sensitive_features,
dictionary=dic)
As in the first tutorial, from now on, you rely on different functions depending on the development environment you use.
Using a Jupyter Notebook
Start by using the function runJ to start FixOut.
fxo.runJ(fxa, show=False)
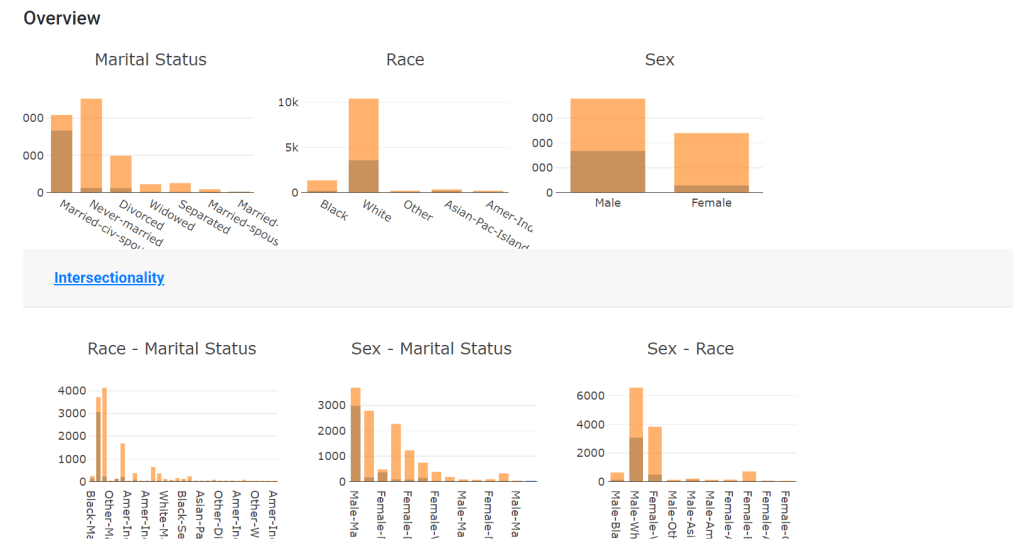
To check the distribution of data centred on sensitive features, you can use the method data_distribution indicating the name of the data slice you want to analyse.
fxo.data_distribution("Testing")
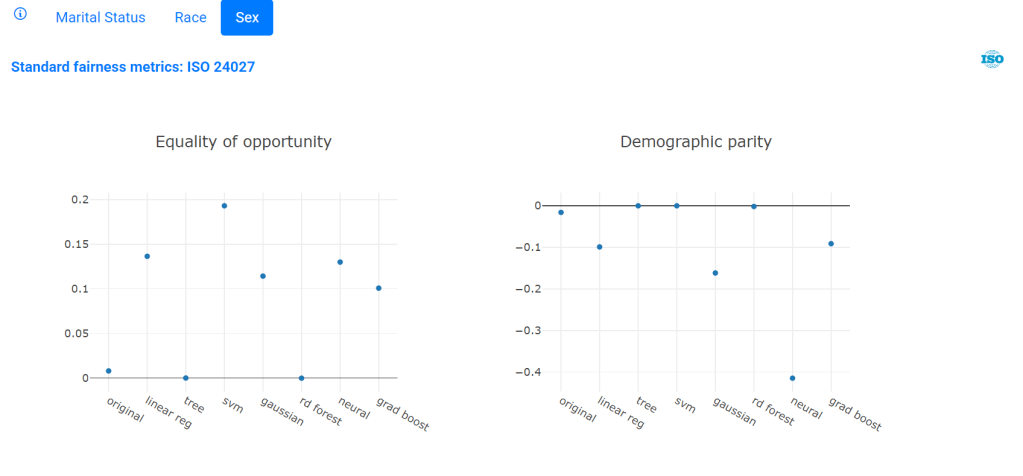
You can also check the calculated fairness metrics by calling the function fairness.
fxo.fairness()